Resources for Low Resource Machine Translation
Ziyi Zhu / November 23, 2022
7 min read • ––– views
There are a wide variety of techniques to employ when trying to create a new machine translation model for a low-resource language or improve an existing baseline. The applicability of these techniques generally depends on the availability of parallel and monolingual corpora for the target language and the availability of parallel corpora for related languages/ domains.
Common scenarios
Neural Machine Translation
Neural Machine Translation (NMT) gives a state-of-the-art performance with unprecedented accuracy and has been adopted by large-scale online systems. But this is only for languages with a huge amount of parallel data (tens of millions of sentences). We also have subpar performance for informal languages (i.e. social media), spoken dialects and narrow domains.
NMT performance drops drastically when the training data is limited, for instance, less than several hundred sentences.
There are mainly two approaches on low-resource MT:
- Utilizing the resource of unlabelled monolingual data (Semi-supervised/Unsupervised Learning)
- Sharing between low-resource and high-resource language pairs (Transfer Learning)
Scenario #1 - The data you have is super noisy (e.g., scraped from the web), and you aren't sure which sentence pairs are "good"
Scenario #2 - You don't have any parallel data for the source-target language pair, you only have monolingual target data
Unsupervised Learning
When we have no data in low-resource language, we need to recreate a machine translation system using the monolingual datasets. We can have two sets of embeddings trained independently on monolingual data. The goal is then to learn a mapping between the two sets such that translations are close in the shared space by exploiting the similarities of monolingual embedding spaces.
Scenario #3 - You only have a small amount of parallel data for the source-target language pair, but you have lots of parallel data for a related source-target language pair
Cross-lingual Transfer Learning
It is possible to take massively multilingually trained neural MT systems (e.g. trained on 50+ languages) and adapt them to new languages that have very little data (e.g. 5000 or so sentences). We can use the method of similar language regularization which is training on another similar language when adapting to new languages.
The concept of multi-lingual training is to train a large multi-lingual system and apply it to a low-resource language. There a two paradigms for pre-training:
- Warm start training: when we see some data from low-resource language.
- Cold start training: when we have no data in the test language when we first initialize the model.
We can achieve rapid adaptation to low-resource languages with proper regularization. However, it is hard to get word embeddings set up from the same distribution across the languages as they might have different domains.
It is also possible to do fully unsupervised adaptation to new languages by simply applying an existing MT system to new languages. We can create a machine learning translation system by transferring across language boundaries.
Scenario #4 - You only have a small amount of parallel data for the source-target language pair, but you have lots of monolingual data for the target and/or source language
We are able to achieve human-level performance in some languages in some domains under certain conditions. Here are a few key factors of success:
- Nowadays we have big data (parallel & monolingual datasets), big models & big computing resources in order to train the models and run them efficiently.
- Better architectures like transformers.
- Better learning algorithms like back-translation (BT), so we can leverage the large corpus of unlabelled monolingual data and better adapt to the test domain.
Back-translation
Back-translation makes use of an NMT system that is trained in the reverse translation direction and is then used to translate target-side monolingual data back into the source language. The resulting sentence pairs constitute a synthetic parallel corpus that can be added to the existing training data to learn a source-to-target model.
There are 6000+ languages in the world, but very few of them enjoy large parallel resources. In addition to back-translation, we also have the following techniques:
- Initialization and ways to pre-train the neural networks.
- Multi-lingual training, in which we can train related language pairs as auxiliary tasks. We can have a lot of parallel sentences of languages that are close in linguistic terms as the source or target.
- Collect Noisy parallel data in an automated manner from ParaCrawl and augment the original dataset.
Problem: The distribution of languages against the number of people who speaks them is heavily skewed and the tail is very long. For many languages, these methods are not applicable because of a lack of data. The less supervision we have, the harder is it to generalize well.
Source Target Domain Mismatch
The Place Effect: Content produced in blogs, social networks, news outlets etc. varies with the geographic location.
The place effect is even more pronounced in low-resource machine translation when the source and target geographic locations are typically farther apart and cultures have more distinct traits.
The place effect makes the machine translation problem even harder, because of source/target domain mismatch. Difficult to learn when there are few data points and the distribution is different, with few correspondences, learning the alignment is difficult.
Considering the source domain and target domain, although the backward model is trained with the parallel dataset which contains mixed-domain data, most of the back-translated data is out-of-domain. STDM can be easily simulated using public benchmarks.
Self-training
This is where semi-supervised learning comes in. In taking a semi-supervised approach, we can train a classifier on the small amount of labelled data, and then use the classifier to make predictions on the unlabelled data which can be adopted as ‘pseudo-labels’ in subsequent iterations of the classifier. This specific technique is called self-training.
There are a few reasons why self-training works:
- The model learns the decoding process. We use beam search to generate translation in the forward pass, but retraining uses token-level cross-entropy loss. Therefore, the performance of greedy search after ST is much closer to beam search.
- We normally add noise in source sentences, and the models learn to map semantically similar input sentences into the same target.
Iterative ST is akin to label propagation. Self-training works well when there is little monolingual data on the target side and when there is an extreme source/target domain mismatch. Self-training is complementary to back-translation. They can be combined in an iterative manner.
Scenario #5 - You have a small amount of parallel data for the source-target language pair, but you also have a lot of parallel data for other language pairs
Meta-learning
Our goal is to transfer the knowledge from high-resource languages that can benefit training for any extremely low-resource languages, a.k.a. learning to learn translation for low-resource languages. Meta-learning tries to solve the problem of fast-learning on new training data.
The basic concept is as follows:
- During training, we can learn a good initialization for adaptation by repeatedly simulating low-resource language setups on high-resource languages.
- During testing, we adapt the trained initialization on real low-resource languages.
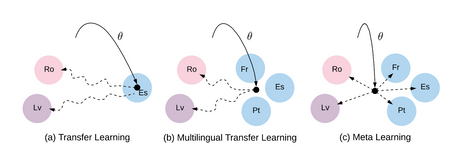
The underlying idea of MAML is to use a set of source tasks to find the initialization of parameters from which learning a target task would only require only a small number of training examples.